Pedestrain trajectory
Questions: 1. only pedestrain relation considered? hoe about environment 2. what is the general framework for pedestrain trajectory prediction.
SGCN: Sparse Graph Convolution Network for Pedestrain Trajectory Prediction (CVPR2021)
SGCN framework
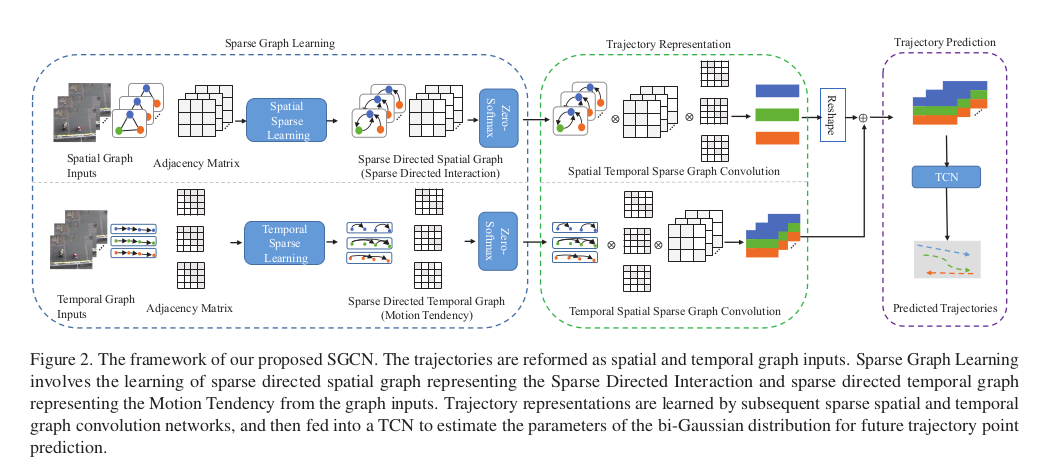
- superfulous interactions:
- dense interaction -> one pedestrain is related to all other pedestrains while in fact it is not
- sparse undirected -> equal interactions for a pair of pedestrains
- spatial GCN -> sparse directed -> not all pedestrains + not equal interaction
- temporal GCN -> motion tendency
Disentangled Multi-Relational Graph Convolutional Network for Pedestrian Trajectory Prediction (AAAI2021)
- Use CNN to generalize complex interpersonal relations
- a graph representation: node as pedestrian, edges correspond to distance
challeges
- only simple social relationship like collision avoidance is aggregated
- modelling social norms is not suitable for determining the end-points of pedestrians in the last frame (over-avoidance)
contributions
- disentangled multi-scale aggregation to clearly distinguish between relevant pedestrians
- multi-relational GCN to extract sophisticated social interaction in a scene.
- a global temporal aggregation to compensate accumulated errors from over-avoidance.
Gaze target estimation
Dual Attention Guided Gaze Target Detection in the Wild
- challenges:
- prior works: gaze direction in 2D representations + barely depth-channel gaze. forward, backward, sideward. (refer to one person)
- salient objects from 2d cues. two candidates different depth along same gaze direction, hard to tell apart. (refer to one person with the scene understanding)
- fixation inconsistency: facing forward looking downward.
- solutions:
- estimate 3D gaze direction from head image.
- dual attention module -> depth-aware perspective in the scene
- ?hasn’t found effective solution in the paper? -> solved in the first stage? so is it still an independent challenge? or should be merged to the first challenge?
ESCNet: Gaze Target Detection with the Understanding of 3D Scenes
- hard to handle: multiple salient objects lie in the same depth layer and field of view. occlusion plays an important role in gaze estimation , one cannot see through occluders.
- 3D geometry could br reconstructed by absolute depth and camera parameters
FOV-based initial heatmap.
Multimodal Across Domains Gaze Target Detection
- gaze target detection also referred as gaze-following
- false detections occur when there are multiple object-of-interests at different depths but along with the subject’s gaze direction
- ‘dual’ potentially being error-prone in real-life processing, e.g., when the eyes are not visible or not detectable
- ‘ESCNET’ auxiliary estimating depth, depend on depth and pseudo labels.
- not require gaze angles as supervision
- only spatial processing, but still detect gaze target
- use depth image
how different modalities should be jointly learned for performing effective gaze target detection
- solve domain shift problem
Beyon 3D Siamese Tracking: A motion-Centric Paradigm for 3D single Object Tracking in Point Clouds
- point clouds are usually textureless and incomplete, which hinders effective appearance matching.
- Overlook motion clues among targets.
- propose a motion-centric paradigm
- $M^2-Track$ localizes the target within successive frames via motion transformation.
- refines the target box through motion-assisted shape completion
Motivation
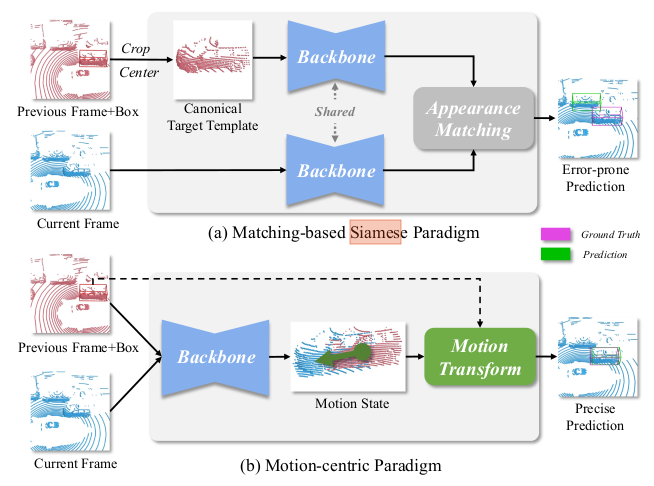
- the upper one obtain a canonical target template using the previous target box and search for the target in thecurrent frame according to the matching similarity. It is sensitive to distractors
- The bottom one learns relative target motion from two consecutive frames. Robustly localize the target.
framework
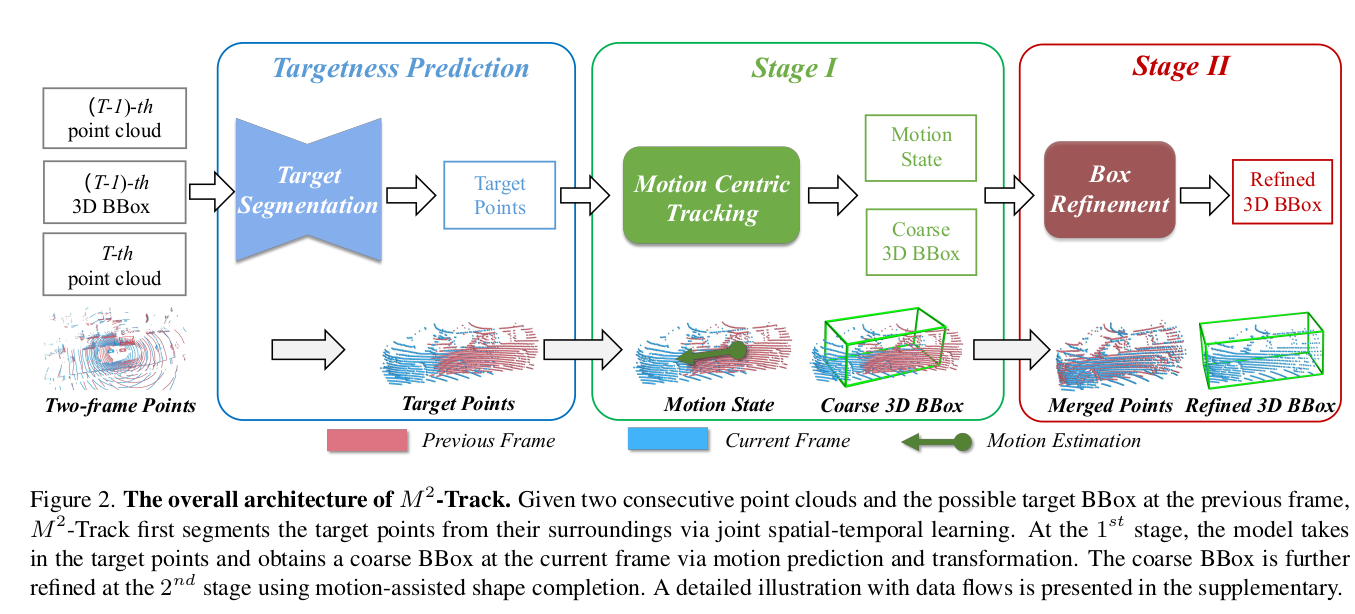
-
input: last point cloud, last 3D BBox, current point cloud
-
output current 3D BBox.
-
? how many frame used and how many frame predicted.
- 1 frame used, 1 frame predicted.
-
quick comment: this task is not suitable for our goal. But it gives a good benchmark for kitti dataset.
Motion CNN
- plan a safe and efficient route.
- a baseline form multimodal motion prediction.
explanation
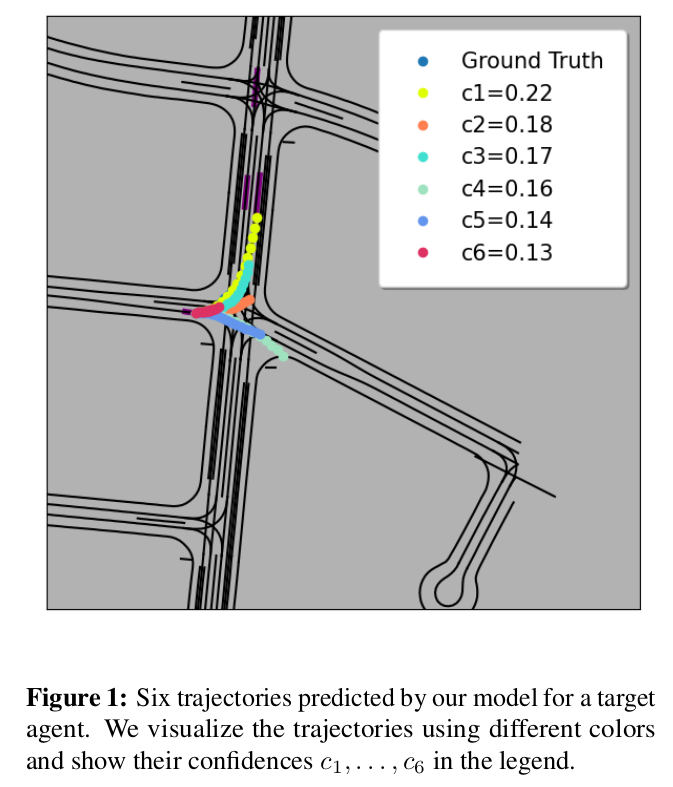
framework
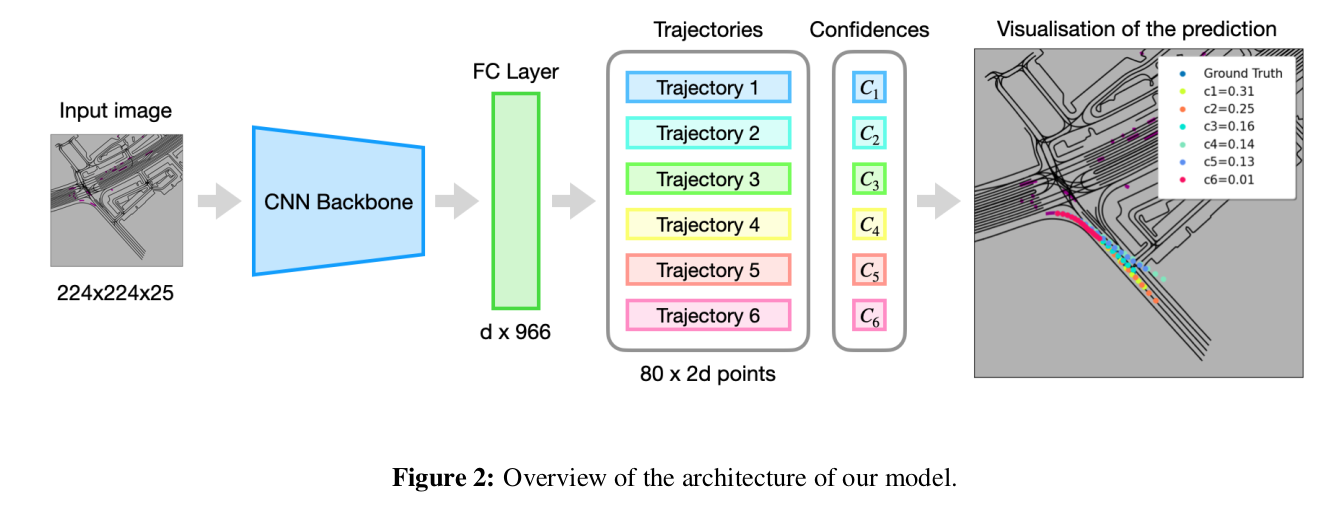
- input: image
- output trajectories.
- use 1 second of images to predict 8 seconds’.
3D Multi-Object Tracking in Point Clouds Based on Prediction confidence-Guided Data Association
- 3D multi-object tracker to more robustly track objects that are temporarily missed by detectors.
- a predictor employs constant acceleration motion model to estimate future positions and prediction confidence.
- a new pairwise cost.
Multimodal Trajectory Prediction Conditioned on Lane-Graph Traversals
- Predicting the future motion of surrounding vehicles requires reasoning about the inherent uncertainty in driving behavior.
- Early works encodes HD maps using a rasterized bird’s eye view image.
- Recent wotks represent lane polylines as nodes of a graph.
- Represent HD map as a graph and encode the input context into a single context vector.
challenges:
- The prediction header go off the road, violate traffic rules because of the complex mapping.
- lateral or route variability (e.g. will the driver change lane, will they turn right etc.). longitudinal variability (will the driver accelerate, brake, maintain spped)
insights
- graph structure of the scene explicitly model the lateral or route variability in trajectories
- predictions conditioned on traversals:
- selectively aggregate part of scene context by sampling path traversals from a learned policy
- it lessens representational demands on the output decoder.
- the probabilistic policy leads to adiverse set of sampled paths.
- latent variable for longitudinal variability:
- condition the predictions with a sampled latent variable.
- enable to predict distinct trajectories even for identical path traversals.
method
- predict the future trajectories of vehicles of interest,
- conditioned on
- their past trajectories
- the past trajectories of nearby vehicles and pedestrians
- the HD map of the scene
- represent the scene, predict in the bird’s eye view and use an agent-centric frame of reference aligned along the agent’s instantaneous direction of motion.
Trajectory representation
$$s_{-t_h:0}^i=[s_{-t_h}^i,\cdots,s_{-1}^i,s_{0}^i]$$ $$s_t^i = [x_t^i, y_t^i, v_t^i, a_t^i, w_t^i,I_t^i]$$
HD maps as lane graphs
- Nodes: lane centerlines $f_{1:N}^v = [f_{1}^v, cdots,f_{N}^v ]$, $f_n^v = [x_n^v, y_n^v, \theta_n^v, I_n^v]$
- Edges: successor edges->legal route; proximal edges-> lane changes
Output representation
K trajectories.
Model
- graph encoder: forms the backbone of our model, outputs representations for each node of the lane graph, incorporate HD map and surrounding agent context.
- policy header: output a discrete probability distribution over outgoing edeges at each node, allowing us to sample paths in the graph.
- trajectory decoder: output trajectories conditioned on paths traversed by the policy and a sampled latent variable.
Encoding scene and agent context
- GRU encoders: target vehicle trajectory $s_{-t_h:0}^0$ -> $h_{motion}$; surrounding vehicle trajectories $s_{-t_h:0}^i$ -> $h_{agent}^i$; node features $f_{1:N}^v$->$h_{node}^v$.
- agent node attention: update node encodings with nearby agent encodings. keys and values from $h_{agent}^i$, query by $h_{node}^v$
- output of agent-node-attention as the attention mask for GAT. Only attended nodes are employed for updating
An explanation of Q, K, V
The Seq2Seq task always has encoder+decoder. The encoders job is to take in an input sequence and output a context vector/thought vector. The context vector is then input to decoder.
However, the performance drops drastically for longer sentences.
One solution is to use skip-connection, by simple concatenation or summing up. -> assume all hidden states are equally important.
So attention (dynamic weighting) is brought in.
An attention mechanism calculates the dynamic weights representing the relative importance of the inputs in the sequence (keys) for the particular output (query). Multiplying the dynamic weights with the input sequence (values) will then weight the sequence.
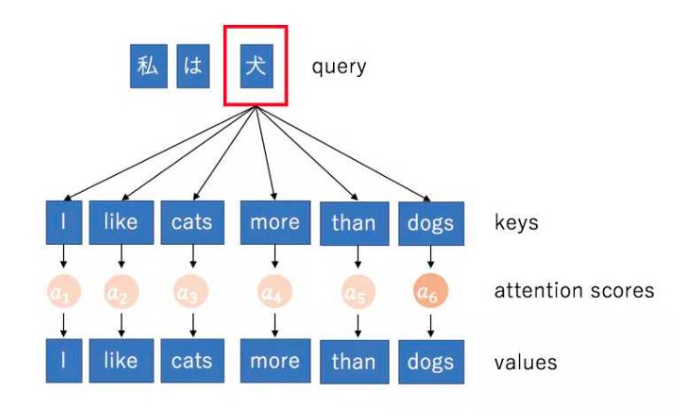
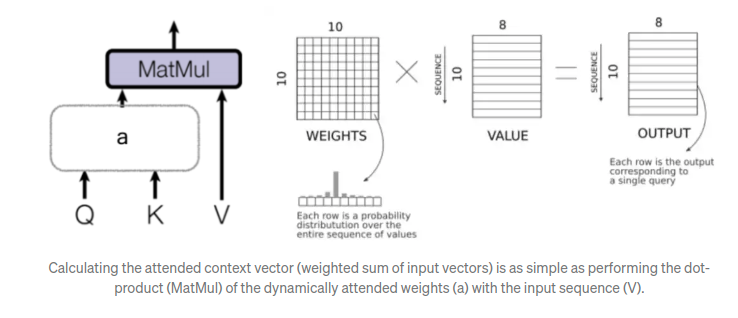
The exact values for Q,K, and V depend on exactly which attention mechnism is being referred to. For the trasformer, 3 types: 1. Encoder Attention, 2, Decoder Attention, 3. Encoder-decoder Attention. (Here for reference)
Discrete policy for graph traversal
- A policy $\pi_{route}$ for graph traversal -> sampled roll-outs of the policy correspond to likely routes the target might take in the future.
- policy: a discrete probability distribution over outgoing edges at each node.
- additionally add an edge to an end state, terminate at a goal location. $$score(u,v)=MLP(concat(h_{motion}, h_{node}^u, h_{node}^v, 1_{(u,v)\in E}))$$ $$\pi_{route}(v|u) = softmax({score(u,v)|(u,v)\in E})$$ $$L_{BC} = \sum_{(u,v)\in E_{g,t}}-\log(\pi_{route}(v|u))$$